
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
- ubuntu
- Kubernetes
- Ai
- Linux
- github
- Lv 2
- 알고리즘
- docker
- 자바
- 코딩테스트
- 프로그래머스
- Java
- 리눅스
- 머신러닝
- 파이썬
- db
- git
- 자료구조
- Python
- 코테
- MLOps
- 우분투
- DevOps
- 정처기
- 데이터베이스
- 인공지능
- 쿠버네티스
- programmers
- mysql
- LV 0
- Today
- Total
Myo-Kyeong Tech Blog
[AI / 데이터분석 ] 교차 검증(Cross Validation) - KFold 와 StratifiedKFold 본문
교차 검증 ( Cross Validation ) 이란?
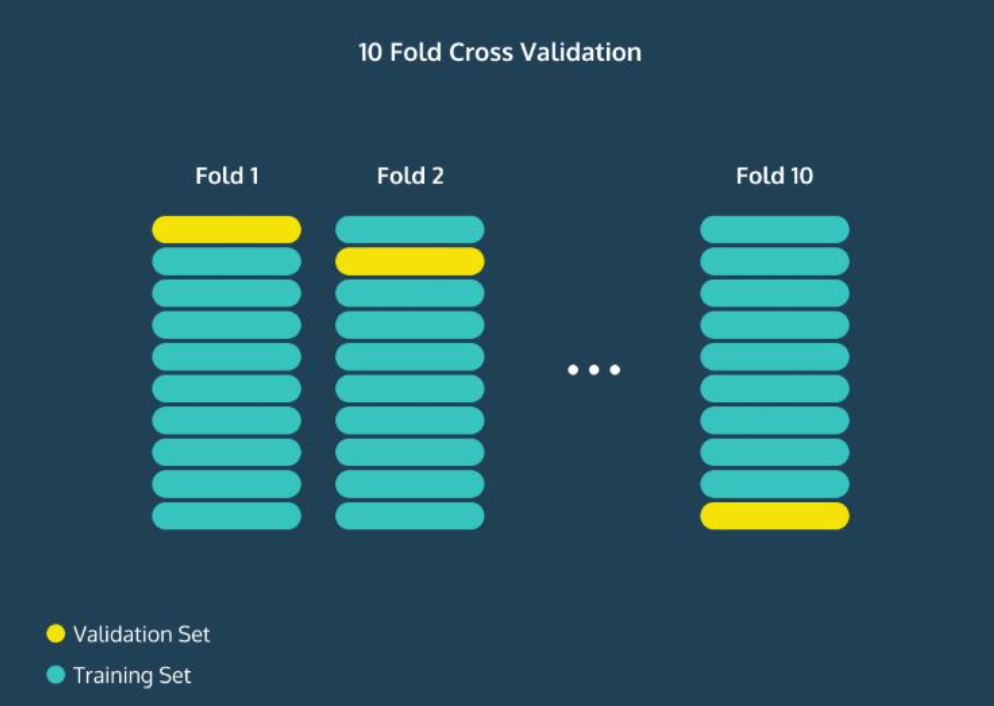
교차 검증 ( Cross Validation ) 은 머신러닝 모델의 일반화 성능을 측정하는 통계적 방법입니다. 데이터를 여러 개의 부분집합 (또는 "fold")으로 나누고 각 부분집합을 차례로 테스트 데이터로 사용하고 나머지를 훈련 데이터로 사용하는 방법입니다.
교차 검증 ( Cross Validation ) 을 사용하는 이유
교차 검증을 사용하는 주요 목적은 모델의 과적합을 방지하고, 데이터를 최대한 효율적으로 활용하여 일반화 성능을 높이기 위해서 입니다. 교차 검증을 통해 얻은 여러 성능 지표들의 평균을 내어 모델의 성능을 추정하면, 학습 / 테스트 분할로 얻은 성능 추정보다 더 신뢰성이 높은 추정을 할 수 있습니다.
K-Fold
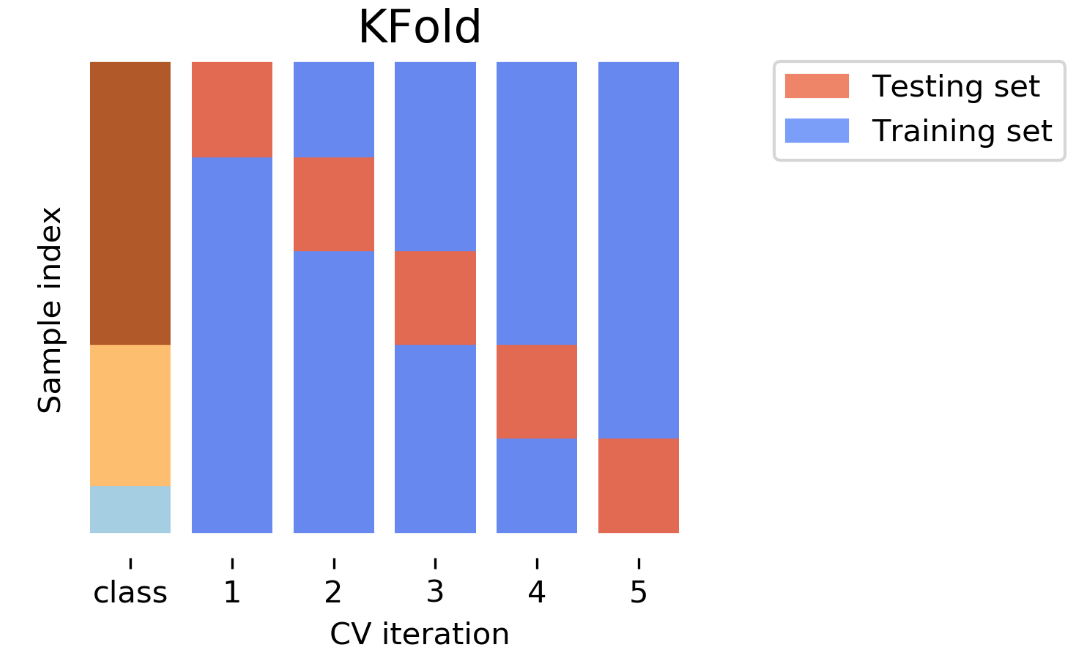
K-Fold 교차 검증은 데이터를 k개의 동일한 크기의 부분집합으로 나누는 방법입니다. 각 반복에서 한 부분집합은 테스트 데이터로, 나머지 부분집합은 훈련 데이터로 사용합니다.
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
# KFold 객체 생성
kfold = KFold(n_splits=5, shuffle=True, random_state=42)
# 모델 객체 생성
model = ...
# cross_val_score 함수를 이용해 K-Fold 교차 검증 수행
scores = cross_val_score(model, X, y, cv=kfold)
# 검증 점수 평균 계산
average_score = scores.mean()
Stratified K-Fold
데이터의 클래스가 불균형일 경우, K-Fold 로 교차 검증을 사용하면 각 fold에 모든 클래스의 데이터가 고르게 분포하지 않을 수 있습니다. 이런 경우 Stratified K-Fold 교차 검증을 사용하면 유용합니다. Stratified K-Fold는 전체 데이터셋의 클래스 비율에 맞게 데이터를 나눕니다.

from sklearn.model_selection import StratifiedKFold
from sklearn.model_selection import cross_val_score
# StratifiedKFold 객체 생성
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
# 모델 객체 생성
model = ...
# cross_val_score 함수를 이용해 Stratified K-Fold 교차 검증 수행
scores = cross_val_score(model, X, y, cv=skf)
# 검증 점수의 평균 계산
average_score = scores.mean()'AI' 카테고리의 다른 글
| [ AI / 데이터분석 ] 데이터 전처리 - 스케일링(Scaling) (0) | 2023.05.21 |
|---|---|
| [AI / 데이터분석 ] 데이터 전처리 - Label Encoder와 One-Hot Encoder (0) | 2023.05.14 |
| [AI / 데이터분석 ] Overfitting과 Early Stopping (0) | 2023.05.10 |
| [AI / 데이터분석] 지도학습 - 회귀분석과 분류분석 (0) | 2023.05.09 |
| [ AI / 데이터분석 ] 인공지능 개념 정리 - 경사하강법, 손실함수, 학습률 (0) | 2023.05.09 |


