
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |
Tags
- 머신러닝
- MLOps
- git
- 자바
- 코테
- 인공지능
- 코딩테스트
- Kubernetes
- 쿠버네티스
- LV 0
- 파이썬
- DevOps
- 알고리즘
- 자료구조
- ubuntu
- Python
- 정처기
- Ai
- github
- programmers
- 프로그래머스
- 우분투
- 데이터베이스
- docker
- mysql
- 리눅스
- db
- Java
- Lv 2
- Linux
Archives
- Today
- Total
Myo-Kyeong Tech Blog
[AI / 데이터분석 ] Overfitting과 Early Stopping 본문
728x90
반응형
과적합 ( Overfitting )

과적합(Overfitting)은 머신러닝 모델이 학습 데이터에 과도하게 최적화되는 현상을 말합니다. 이러한 현상은 모델이 학습 데이터의 특징뿐만 아니라 노이즈까지 학습하게 되어, 일반화 ( generalization ) 성능을 저하시키는 결과를 초래합니다.
즉, 과적합이 발생한 모델은 학습 데이터에 대해 매우 높은 정확도를 보이지만, 테스트 데이터나 실제로 새롭게 들어오는 데이터에 대한 예측 성능은 상대적으로 떨어지게 됩니다. 이는 모델이 학습 데이터에 지나치게 의존하여 새로운 데이터에 대한 유연한 대응이 어려워짐을 의미합니다.
Early Stopping
Early Stopping은 과적합을 방지하기 위한 기법 중 하나입니다. 이 기법은 학습 도중에 검증 데이터 ( validation data ) 에 대한 성능이 일정 기간 동안 개선되지 않을 경우, 학습을 조기에 종료시키는 방법입니다.
딥러닝 모델 학습 과정에서는 일반적으로 에포크 (epoch) 수를 지정하고 모델을 학습시킵니다. 하지만 너무 많은 에포크를 학습하게 되면 모델이 학습 데이터에 과도하게 최적화되어 과적합이 발생할 수 있습니다. 이를 방지하기 위해 early stopping 은 모델의 검증 성능이 일정 기간 동안 향상되지 않으면 학습을 멈추는 방식입니다.
from keras.models import Sequential
from keras.layers import Dense
from keras.callbacks import EarlyStopping
# 데이터셋 불러오기
X_train = ...
y_train = ...
X_test = ...
y_test = ...
# Sequential 모델 생성
model = Sequential()
model.add(Dense(64, input_dim=X_train.shape[1], activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# 모델 컴파일
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# EarlyStopping
es = EarlyStopping(monitor='val_loss', mode='min', verbose=1, patience=10)
# 모델 훈련
model.fit(X_train, y_train, validation_data=(X_test, y_test), epochs=100, batch_size=32, callbacks=[es])
Overfitting과 Early Stopping 실습 - iris 데이터 예제
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.datasets import load_iris
import time
#1. 데이터
datasets = load_iris()
x = datasets['data']
y = datasets.target
print(x.shape, y.shape) #(150, 4) (150,)
x_train, x_test, y_train, y_test = train_test_split(
x, y, train_size=0.6, random_state=100, shuffle=True
)
print(x_train.shape, y_train.shape) #(105, 4) (105,)
print(x_test.shape , y_test.shape) #(45, 4) (45,)
#2. 모델 구성
model = Sequential()
model.add(Dense(100, input_dim = 4))
model.add(Dense(100))
model.add(Dense(100))
model.add(Dense(50))
model.add(Dense(3, activation='softmax'))
#3. 컴파일 , 훈련
model.compile(loss='sparse_categorical_crossentropy', optimizer='adam',
metrics=['accuracy','mse'])
start_time = time.time()
hist = model.fit(x_train, y_train, epochs = 500, batch_size = 128,
validation_split=0.2)
end_time = time.time() - start_time
#4. 평가, 예측
loss, acc, mse = model.evaluate(x_test, y_test)
y_predict = model.predict(x_test)
print(y_predict)
print('loss : ', loss)
print('acc : ', acc)
print('걸린 시간 : ', end_time)
#시각화
import matplotlib.pyplot as plt
from matplotlib import font_manager, rc
plt.figure(figsize=(9,6))
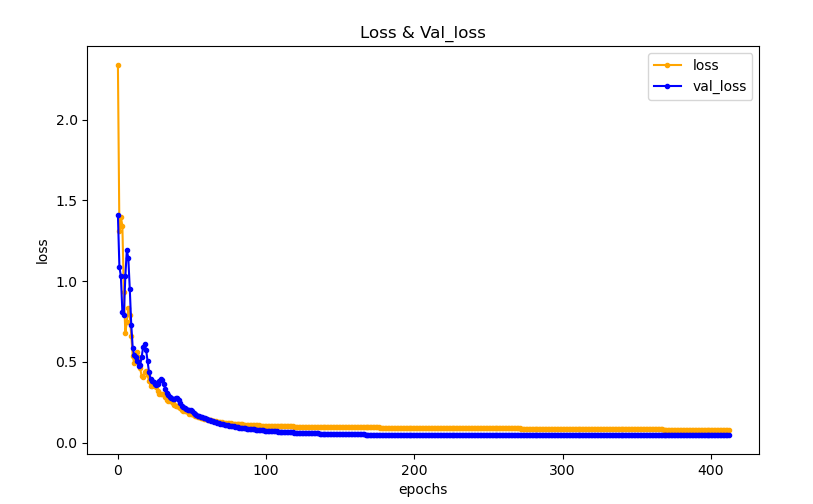
plt.plot(hist.history['loss'], marker='.', c='orange', label='loss')
plt.plot(hist.history['val_loss'], marker='.', c='blue', label='val_loss')
plt.title('Loss & Val_loss')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
plt.show()

Epoch = 500 으로 했을 때 과적합이 발생하는 것을 볼 수 있습니다.
## earlystopping
from keras.callbacks import EarlyStopping
earlyStopping = EarlyStopping(monitor = 'val_loss', patience=100, mode='min',
verbose = 1, restore_best_weights = True ) #restore_best_weights의 default는 False이므로 True로 꼭 변경!!
start_time = time.time()
hist = model.fit(x_train, y_train, epochs = 5000, batch_size = 128,
validation_split=0.2,
callbacks=[earlyStopping],
verbose=1) #validation data => 0.2 (train: validation : test = 6:2:2)
end_time = time.time() - start_time
728x90
반응형
'AI' 카테고리의 다른 글
| [AI / 데이터분석 ] 교차 검증(Cross Validation) - KFold 와 StratifiedKFold (0) | 2023.05.20 |
|---|---|
| [AI / 데이터분석 ] 데이터 전처리 - Label Encoder와 One-Hot Encoder (0) | 2023.05.14 |
| [AI / 데이터분석] 지도학습 - 회귀분석과 분류분석 (0) | 2023.05.09 |
| [ AI / 데이터분석 ] 인공지능 개념 정리 - 경사하강법, 손실함수, 학습률 (0) | 2023.05.09 |
| [ AI / 데이터분석 ] 인공지능 개념 정리 - 퍼셉트론 ( Perceptron ) (0) | 2023.05.08 |
'AI' Related Articles
more


