
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 알고리즘
- 자료구조
- 파이썬
- DevOps
- docker
- Java
- programmers
- 정처기
- mysql
- git
- 데이터베이스
- Lv 2
- 머신러닝
- 코딩테스트
- 리눅스
- 프로그래머스
- 자바
- github
- ubuntu
- 코테
- 인공지능
- Linux
- Ai
- Kubernetes
- db
- 쿠버네티스
- LV 0
- Python
- MLOps
- 우분투
Archives
- Today
- Total
Myo-Kyeong Tech Blog
[ AI / 데이터분석 ] 데이터 전처리 - 스케일링(Scaling) 본문
728x90
반응형
데이터 스케일링 ( Scaling )
- 다양한 특성의 값을 일정한 범위 또는 표준에 맞게 조정하는 과정
- 특성 간의 비교를 가능하게 함
- 모델의 성능을 향상시키고, 계산의 수치적 안정성을 제공.
데이터 스케일링 ( Scaling ) 이 필요한 경우
- 특성의 단위가 다른 경우
- 경사 하강법을 사용한 모델 ( 예 : 선형 회귀, 로지스틱 회귀, 신경망 등)
- 거리 기반 알고리즘 ( 예 : K-NN, SVM )
예를 들어, 집의 가격을 예측하는 모델을 만들려고 합니다. 특성으로는 집의 크기 (평방 미터), 방의 수(개수), 위치 (위도와 경도) 등이 있다면, 이 특성들은 모두 다른 단위와 범위를 가지고 있습니다. 집의 크기는 수백에서 수천, 방의 수는 1에서 10사이, 위치 좌표에 따라 수백에서 수천의 범위를 가질 수 있습니다.
이런 상황에서, 만약 스케일링을 하지 않고 학습한다면, 크기가 큰 특성 ( ex - 집의 크기 ) 이 모델의 결과에 더 큰 영향을 미치고, 방의 수 같은 작은 범위의 특성이 중요함에도 불구하고 그 특성이 무시되는 결과를 초래할 수 있습니다.
또한, k- 최근접 이웃 (K-NN)이나 서포트 벡터 머신 (SVM) 과 같은 거리 기반의 머신러닝 알고리즘들은 특성의 스케일에 매우 민감합니다. 예를 들어 특성 A의 범위가 1-10이고, 특성 B의 범위가 1-1000이라고 한다면 특성 B의 스케일이 더 크므로 거리 계산에 더 큰 영향을 끼치게 됩니다. 그 결과 특성 A를 무시할 수 있으므로 모든 특성을 동일한 범위로 스케일링 해야 합니다.
다양한 스케일링 방법
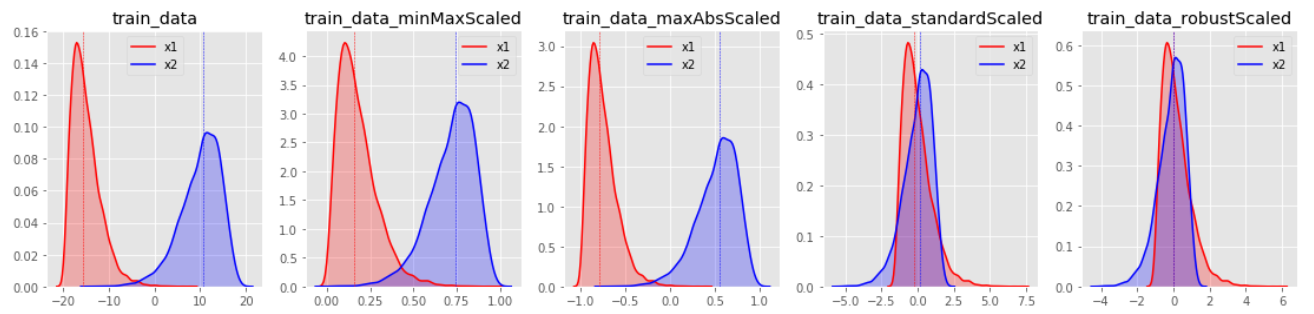
MinMaxScaler
- 특성들을 특정 범위 ([0, 1])로 스케일링
- 이상치에 매우 민감하며, 분류보다 회귀에 유용함
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaled_data = scaler.fit_transform(data)
StandardScaler
- 특성들의 평균을 0, 분산을 1로 스케일링 (즉, 특성들을 정규분포로 만듬 )
- 이상치에 매우 민감하며, 회귀보다 분류에 유용함.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaled_data = scaler.fit_transform(data)
MaxAbsScaler
- 각 특성의 절댓값이 0과 1 사이가 되도록 스케일링
- 즉, 모든 값은 -1과 1사이로 표현되며, 데이터가 양수일 경우에는 MinMaxScaler와 동일
from sklearn.preprocessing import MaxAbsScaler
scaler = MaxAbsScaler()
scaled_data = scaler.fit_transform(dat
RobustScaler
- 평균과 분산 대신 중간 값과 사분위 값을 사용
- 이상치 영향을 최소화 할 수 있음.
from sklearn.preprocessing import RobustScaler
scaler = RobustScaler()
scaled_data = scaler.fit_transform(data)
# 스케일링
sts = StandardScaler()
mms = MinMaxScaler()
mas = MaxAbsScaler()
rbs = RobustScaler()
qtf = QuantileTransformer() # QuantileTransformer 는 지정된 분위수에 맞게 데이터를 변환함.
# 기본 분위수는 1,000개이며, n_quantiles 매개변수에서 변경할 수 있음
ptf1 = PowerTransformer(method='yeo-johnson') # 'yeo-johnson', 양수 및 음수 값으로 작동
ptf2 = PowerTransformer(method='box-cox') # 'box-cox', 양수 값에서만 작동
scalers = [sts, mms, mas, rbs, qtf, ptf1, ptf2]
for scaler in scalers:
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
model = CatBoostClassifier( ) # 사용하는 모델 입력
model.fit(x_train, y_train)
y_predict = model.predict(x_test)
result = accuracy_score(y_test, y_predict)
scale_name = scaler.__class__.__name__
print('{0} 결과 : {1:.4f}'.format(scale_name, result), )
728x90
반응형
'AI' 카테고리의 다른 글
| [AI / 데이터분석 ] 교차 검증(Cross Validation) - KFold 와 StratifiedKFold (0) | 2023.05.20 |
|---|---|
| [AI / 데이터분석 ] 데이터 전처리 - Label Encoder와 One-Hot Encoder (0) | 2023.05.14 |
| [AI / 데이터분석 ] Overfitting과 Early Stopping (0) | 2023.05.10 |
| [AI / 데이터분석] 지도학습 - 회귀분석과 분류분석 (0) | 2023.05.09 |
| [ AI / 데이터분석 ] 인공지능 개념 정리 - 경사하강법, 손실함수, 학습률 (0) | 2023.05.09 |
'AI' Related Articles
more


